Mục tiêu cụ thể việc triển khai đề án ngoại ngữ 2020 trong các trường ĐH giai đoạn 2011-2020:
- Đối với các ngành học không chuyên ngữ, sau khi tốt nghiệp sinh viên phải đạt trình độ tối thiểu bậc 3 theo khung năng lực ngoại ngữ; đối với các ngành chuyên ngữ, sinh viên tốt nghiệp CĐ phải đạt trình độ bậc 4, tốt nghiệp ĐH phải đạt trình độ bậc 5 đồng thời được đào tạo ngoại ngữ 2 đạt trình độ bậc 3 khung năng lực ngoại ngữ.
- Triển khai chương trình đào tạo tăng cường môn ngoại ngữ cho khoảng 10% số sinh viên CĐ, ĐH vào năm 2011-2012; 60% vào năm 2015-2016 và 100% vào năm 2019-2020.
- Đến năm 2015, 100% đội ngũ giảng viên ngoại ngữ được đào tạo, bồi dưỡng cả về trình độ chuyên môn lẫn nghiệp vụ sư phạm.
- Đến năm 2020, 100% giảng viên ngoại ngữ của các cơ sở giáo dục ĐH đã được thi tham quan, học tập, bồi dưỡng chuyên môn, nghiệp vụ ở các nước có bản ngữ hoặc ngôn ngữ quốc gia phù hợp với ngoại ngữ đang dạy cho sinh viên.
- Đến năm 2015, 100% các cơ sở giáo dục ĐH đều có các phòng học tiếng nước ngoài, có phòng nghe nhìn, phòng đa phương tiện và có các trang thiết bị thiết yếu đảm bảo đáp ứng cho việc dạy và học ngoại ngữ.
Tuesday, December 27, 2011
Saturday, December 24, 2011
Flash Light - Tin hieu moi chang?
DĐM: Tín hiệu mới của Bộ GD chăng? Phải ghi ngay lại đoạn đo đỏ bôi đậm phía dưới cùng, gì thì gì cứ phải "mách có chứng" :) Nhỡ nó hạ bài nên lưu cache tại đây: http://www.baomoi.com/Chua-benh-cam-va-diec-tieng-Anh-sau-16-nam-hoc/59/7601406.epi
">Ông Nguyễn Ngọc Hùng, Trưởng Bộ phận thường trực Đề án Ngoại ngữ Quốc gia 2020 (Bộ GD-ĐT) cho biết thông tin trên tại hội thảo triển khai đề án dạy và học ngoại ngữ trong các trường ĐH giai đoạn 2011 tổ chức sáng 23/12. Từ kinh nghiệm dự giờ, ông Hùng khái quát "cách học ngoại ngữ ở các trường vẫn theo lối truyền thống. Nghĩa là dạy nhiều nên phải hy sinh phần nói, thậm chí quá chú trọng đến văn bản. Do đó dù học sinh được trang bị 900 tiếng Anh ở phổ thông và 200 tiết tiếng Anh ở ĐH nhưng ra trường vẫn "câm và điếc"."
">Ông Nguyễn Ngọc Hùng, Trưởng Bộ phận thường trực Đề án Ngoại ngữ Quốc gia 2020 (Bộ GD-ĐT) cho biết thông tin trên tại hội thảo triển khai đề án dạy và học ngoại ngữ trong các trường ĐH giai đoạn 2011 tổ chức sáng 23/12. Từ kinh nghiệm dự giờ, ông Hùng khái quát "cách học ngoại ngữ ở các trường vẫn theo lối truyền thống. Nghĩa là dạy nhiều nên phải hy sinh phần nói, thậm chí quá chú trọng đến văn bản. Do đó dù học sinh được trang bị 900 tiếng Anh ở phổ thông và 200 tiết tiếng Anh ở ĐH nhưng ra trường vẫn "câm và điếc"."
Đồng quan điểm, phó Hiệu trưởng Trường ĐH Kỹ thuật Công nghiệp (ĐH Thái Nguyên) Vũ Ngọc Pi đề xuất, nên có lộ trình cụ thể, hợp lí đối với việc đào tạo năng lực tiếng Anh cho SV và giảng viên. Cùng với đó, đội ngũ giảng viên tiếng Anh cần được đi học tập tại các nước nói tiếng Anh. Chú trọng bồi dưỡng khả năng nghe nói cho sinh viên và giảng viên..."Ông Pi cũng cho hay, để nâng chất lượng dạy và học tiếng Anh nhà trường rất chú trọng ngay từ khâu tuyển dụng. Nhiều năm nay trường tuyển giáo viên tiếng Anh phải tốt nghiệp chính quy và bằng phải từ khá trở lên...Tuy nhiên, đến nay trường vẫn chưa có giáo viên nào được đi nước ngoài đào tạo mà mới dừng ở việc đi thăm quan, du lịch nên hiệu quả chưa được cọ sát. Đội ngũ giáo viên dạy tiếng Anh còn thiếu.
Bà Lê Hương cho biết, năm 2012-2015 Cục Đào tạo và hợp tác với nước ngoài sẽ tổ chức bồ dưỡng cho 60% giảng viên ngoại ngữ đi học tập, bồi dưỡng chuyên môn nghiệp vụ ngắn hạn và dài hạn ở nước ngoài. 40% giảng viên còn lại được đưa đi bồi dưỡng vào năm 2016-2020
Wednesday, December 21, 2011
Monday, December 19, 2011
Wednesday, December 14, 2011
Descriptive Statistic, Cross Tabulation, Chi-square with Pivot Table in Excel
Dương Đức Minh: Như đã nói trong bài trước, nếu dùng SPSS thì nhanh, chi tiết và OK rồi nhưng quả thật (mình hỏi khắp rồi, ít người biết, biết không sâu về SPSS ở TN) với Excel ta cũng có thể làm công việc tương tự tuy hơi rắc rối hơn 1 chút nhưng bớt được khoản nhập số liệu, define, compute, code, recode ... so với SPSS. Xin giới thiệu bài viết của anh (chị) Nguyễn Văn Chức đăng trên bis.net
Phân tích dữ liệu với PivotTable trong Excel
Thống kê là nền tảng của khai phá dữ liệu. Vì vậy, hiểu và triển khai được một dự án phân tích dữ liệu thống kê là rất cần thiết và sẽ giúp ích rất nhiều trong quá trình xây dựng các mô hình khai phá dữ liệu phức tạp. Bài viết này nhằm giúp các bạn từng bước triển khai phân tích dữ liệu có được thông qua điều tra bằng bảng câu hỏi (Questionnaires). Bạn không cần phải là chuyên gia về phân tích dữ liệu hay thống kê. Các khái niệm về thống kê và qui trình thực hiện một nghiên cứu thống kê đơn giản như thu thập dữ liệu, mã hóa dữ liệu, phân tích dữ liệu được mô tả từng bước một cách chi tiết bằng MS Excel.
Bài viết trình bày các bước của một nghiên cứu phân tích dữ liệu từ xây dựng dữ liệu mẫu và câu hỏi nghiên cứu, mã hóa dữ liệu, các phân tích đơn giản với thống kê mô tả (Descriptive Statistic) đến các phân tích phức tạp hơn dựa vào Cross tabulation (Pivot Table), kiểm định giả thuyết (Chi-square test).
1. Dữ liệu mẫu và câu hỏi nghiên cứu (Data Example & Research Questions)
Để dễ hình dung, chúng ta bắt đầu với bảng câu hỏi đơn giản gồm 6 câu hỏi liên quan đến khách đến giải trí tại công viên ABC nhằm phân tích, đánh giá mức độ hài lòng của khách với các dịch vụ của công viên ABC. Sau đây là ý nghĩa của các biến sử dụng trong nghiên cứu:
· Family (Gia đình): Đáp viên, đối tượng trả lời câu hỏi, khách.
· Time(thời gian): Thời gian hoạt động của gia đình trong công viên. Tính bằng phút và có kiểu dữ liệu định lượng (quantitative)
· Mode: Loại hình phương tiện mà khách (gia đình) lựa chọn đi đến công viên. Có kiểu dữ liệu định danh (nominal) gồm các giá trị như sau: (1) walk, (2) car, (3) bicycle, (4) bus.
Chú ý: Mỗi gia đình chỉ chọn 1 trong 4 giá trị của Mode
· Activity (hoạt động): Chỉ các hoạt động của gia đình tại công viên, có kiểu dữ liệu định danh và gồm 6 hoạt động như sau: (1) sport, (2) picnic, (3) reading, (4) walk , (5) meditation, (6) jog.
Mỗi gia đình có thể chọn nhiều hoạt động
Satisfaction (sự hài lòng): Đo lường sự hài lòng của khách đến giải trí tại công viên đối với các dịch vụ của công viên, có kiểu dữ liệu thứ bậc (ordinal) gồm 5 mức như sau::
-2 = Rất không hài lòng (Very dissatisfied),
- 1 = Không hài lòng (dissatisfied),
0 = Không quan tâm (indifference),
1 = Hài lòng (satisfied),
2 = Rất hài lòng (Very satisfied).
· Playground (sân chơi trẻ con): Có kiểu dữ liệu định danh, có hai giá trị là Yes và No cho biết công viên có sân chơi cho trẻ con hay không.
Giả sử rằng các câu hỏi điều tra được hỏi với 12 gia đình đã đến công viên giải trí và dữ liệu ban đầu (raw data) thu được như sau:
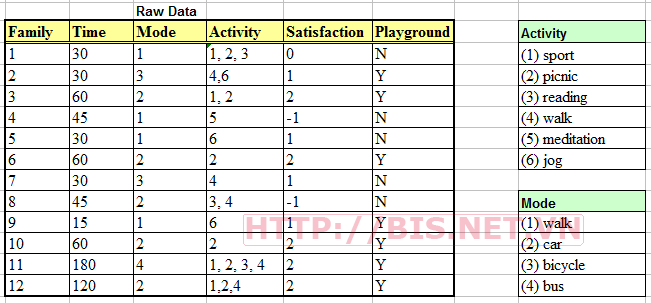
Với những dữ liệu thu được như trên, chúng ta muốn nghiên cứu để làm tăng mức độ hài lòng của khách đến công viên. Câu hỏi nghiên cứu cần trả lời là “Làm sao nâng cao mức độ hài lòng của khách đến vui chơi tại công ty ABC?”
Để trả lời câu hỏi trên, ta phải trả lời các câu hỏi nhỏ sau:
1. Mức độ hài lòng của khách tới vui chơi tại công viên ABC là bao nhiêu?
2. Hoạt động nào được lựa chọn nhiều nhất trong công viên?
3. Khách thường đến công viên bằng phương tiện nào ?
4. Nếu có sân chơi cho trẻ em ở công viên thì liệu mức độ hài lòng của khách có tăng lên không?
5. Có mối quan hệ (tương quan- Correlation) giữa hoạt động (activity) và thời gian hoạt động của khách không?
6. Có mối quan hệ (tương quan) giữa thời gian mà khách lưu lại công viên với phương tiện (mode) mà họ sử dụng để đến công viên không?
Làm sao bạn sẽ trả lời những câu hỏi nghiên cứu này? Các bước sau đây sẽ giúp bạn trả lời các câu hỏi trên. Giả sử rằng dữ liệu thu được ở trên là các mẫu hợp lệ (dù số mẫu rất ít và chỉ dùng để minh họa).
2. Mã hóa dữ liệu từ bảng câu hỏi (Data Coding from Questionnaires)
Chúng ta đã có dữ liệu điều tra từ bảng câu hỏi và chúng ta muốn phân tích dữ liệu đó. Bước đầu tiên của phân tích dữ liệu là mã hóa dữ liệu (data coding). Mã hóa dữ liệu là quá trình chuyển đổi dữ liệu có được từ bảng câu hỏi sang định dạng phù hợp để phân tích (và có thể thực hiện tính toán trên máy tính).
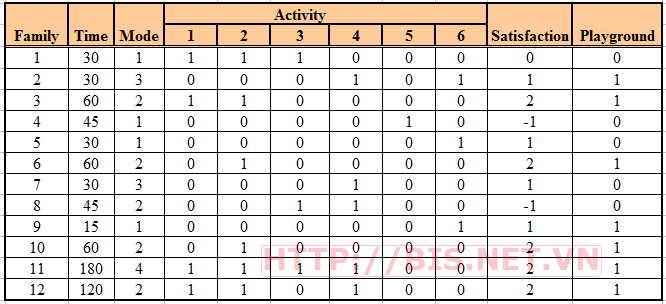
Dữ liệu thu được gồm 6 biến (variable) và chỉ có 2 biến định danh (nominal) là Activity vàPlayground là cần chuyển đổi và 4 biến còn lại đã có kiểu dữ liệu phù hợp (kiểu số).
Biến Activities được chuyển qua kiểu nhị phân chỉ nhận 2 giá trị 1 và 0. (1 có nghĩa là hoạt động đó được chọn và 0 có nghĩa là không chọn hoạt động đó). Ta có 6 hoạt động nên ta chuyển thành 6 cột (mỗi cột tương ứng với 1 hoạt động).
Biến Playground cũng được chuyển sang dạng nhị phân (1 = yes : có sân chơi, và 0 = no: không có sân chơi)
Kết quả của bước mã hóa dữ liệu ta thu được dữ liệu đã mã hóa như sau:
3. Phân tích đơn giản với thống kê mô tả (Descriptive Statistics)
Trong phần này, chúng ta tiến hành phân tích đơn giản đầu tiên với dữ liệu có được sau khi mã hóa bằng cách sử dụng MS Excel để tính toán các thống kê mô tả trên dữ liệu đã mã hóa.
Để thực hiện tính các thống kê mô tả trong Excel ta làm như sau:
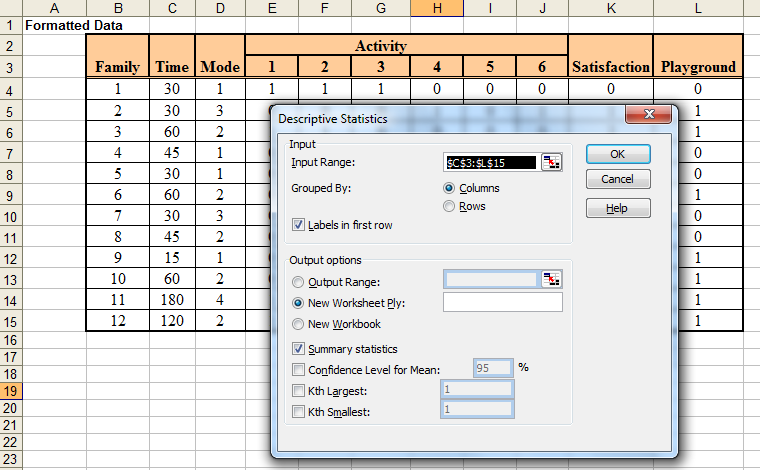
· Click menu Tools - Data Analysis – Descriptive Statistics.
· Thiết lập các tùy chọn cho hộp thoại Descriptive Statistics như hình sau và bấm OK
Kết quả của Descriptive Statistics sau một số thao tác định dạng cho dễ nhìn (bỏ đi các cột tham số giống nhau trong bảng) như sau:
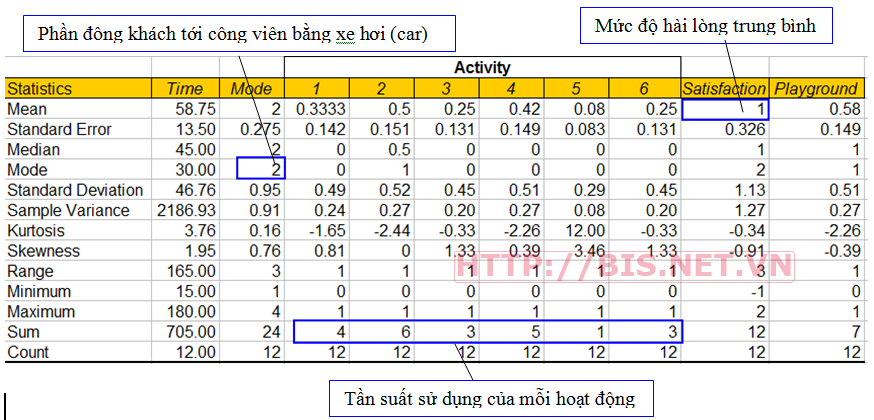
Thống kê mô tả tính toán rất nhiều tham số như bảng trên và giúp ta phân tích đơn giản ban đầu về dữ liệu. Không nên lo lắng nếu không hiểu tất cả các tham số được tính từ thống kê mô tả nên, chỉ nên tập trung vào các câu hỏi nghiên cứu đã đặt ra từ đầu. (đó là lý do vì sao phải đặt ra các câu hỏi nghiên cứu trước khi tiến hành phân tích dữ liệu).
Từ dữ liệu bảng trên, ta thấy rằng mức độ hài lòng (Satisfaction) trung bình là 1 (thang đo mức độ hài lòng có 5 mức độ từ -2 đến 2). Ta có thể kết luận rằng khách khá hài lòng với điều kiện của công viên ABC. Như vậy câu hỏi nghiên cứu 1 về mức độ hài lòng của khách với công viên ABC đã được trả lời.
Cũng từ kết quả tính toán trên, ta có được tần suất sử dụng các hoạt động tại công viên ABC như sau:
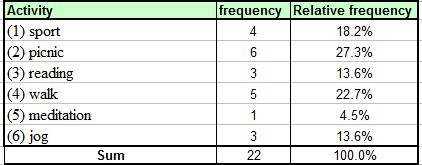
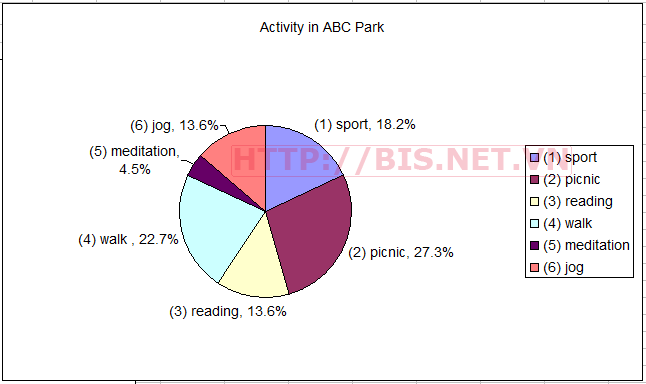
Dựa vào dữ liệu về tần suất các hoạt động trên, ta có thể kết luận phần lớn gia đình tới công viên để hoạt động Picnic (27.3%) hoặc đi bộ (Walk) (22.7%). Phân tích này đã trả lời câu hỏi nghiên cứu 2 : “Hoạt động nào được lựa chọn nhiều nhất trong công viên?”
Từ số Mode của biến Mode (phương tiện) ta có thể kết luận phần lớn khách đến công viên bằng xe hơi (Mode = 2, car). Phân tích này đã trả lời câu hỏi nghiên cứu thứ 3: “Khách đến công viên bằng phương tiện nào?”
4. Phân tích dựa vào bảng chéo (Cross Tabulation)
Trong phần trên, chúng ta đã thực hiện các phân tích đơn giản ban đầu với dữ liệu bằng thống kê mô tả và tần suất từ dữ liệu. Phần này tìm hiểu làm thế nào để phân tích mối quan hệ giữa các biến trong dữ liệu điều tra từ bảng hỏi bằng cách sử dụng bảng chéo (Cross Tabulation) còn gọi là Pivot Table hay contingency table.
Sử dụng dữ liệu đã mã hóa, chúng ta muốn trả lời câu hỏi nghiên cứu tiếp theo:
- Nếu có sân chơi cho trẻ em ở công viên thì liệu mức độ hài lòng của khách có tăng lên không?
- Có mối quan hệ (tương quan) giữa hoạt động (activity) tại công viên mà khách chọn và thời gian (time) mà các gia đình lưu lại công viên không?
- Có mối quan hệ (tương quan) giữa thời gian mà khách lưu lại công viên với phương tiện (mode) mà họ sử dụng để đến công viên không?
Bởi vì các câu hỏi nghiên cứu này về mối quan hệ giữa 2 biến, chúng ta cần sử dụng kỹ thuật phân tích dựa trên Cross Tabulation để trả lời các câu hỏi này. Cross tabulation là bảng tần suất giữa hai hay nhiều biến. Nó có rất nhiều tên gọi khác nhau, các nhà thống kê gọi là Contigency Table trong khi MS Excel gọi là Pivot Table.
Để tạo Pivot Table trong Excel ta tiến hành như sau:
Menu Data – Pivot Table and Pivot Chart Report .
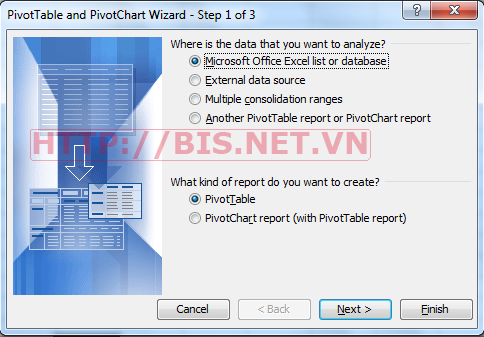
Chọn Next và chọn vùng dữ liệu, xem hình sau:
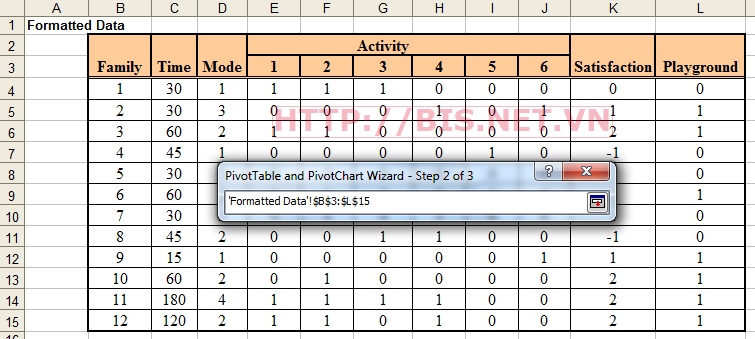
Bấm Next và chọn Layout button
Để trả lời mối quan hệ (relationship) giữa 2 biến Playground và Satisfaction, kéo và thả tên các biến tương ứng ở bên phải vào sơ đồ. Đặt biến Satisfaction trong hàng (row) và biến Playground trong cột (column) và kéo thả biến Satisfaction một lần nữa vào vùng Data .Nó sẽ xuất hiện Sum of Satisfaction. Sau đó, double click vào nút cuối cùng (Sum of Satisfaction ) và Pivot Table Field dialog xuất hiện. Trong mục summarized by chọnCount và click OK 2 lần.
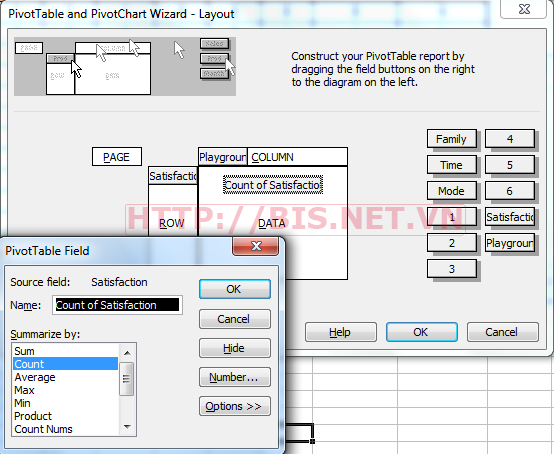
Khi quay trở lại bước 3 của Pivot table wizard, Click Finish button.
MS excel sẽ tự động tạo ra Cross Tabulation table như sau:
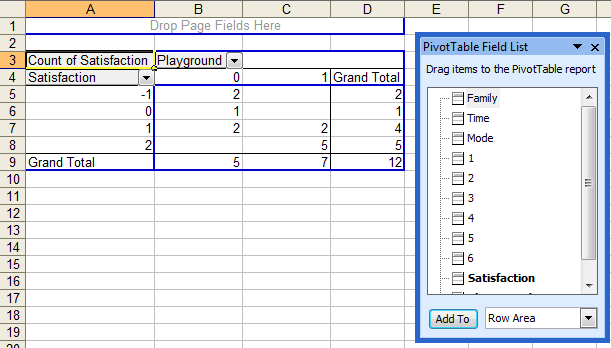
Để thuận lợi cho việc phân tích, bạn có thể copy dữ liệu từ Pivot table ra và dán vào vùng khác (chú ý là sử dụng Edit - Paste Special, chọn value)
Sau khi copy và định dạng lại dữ liệu từ Pivot table, ta tính giá trị kỳ vọng (expected value) theo công thức sau (Giá trị kỳ vọng còn được gọi là giá trị độc lập vì được tính với giá thuyết H0 đúng). Để biết liệu biến Playground có quan hệ với biến Satisfaction hay không, ta thực hiện kiểm định đơn giản gọi là Chi-square test. Chi-square test cho phép kiểm tra tính độc lập của 2 biến trong Contingency table.
Công thức tính giá trị kỳ vọng
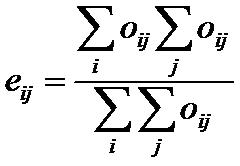
Trong đó Oij là giá trị quan sát (Observe value) tại dòng i cột j
Ý nghĩa của công thức trên là để có được giá trị độc lập tại dòng i cột j, ta nhân tổng của dòng i với tổng của cột j và chia cho tổng của tất cả dữ liệu trong bảng.
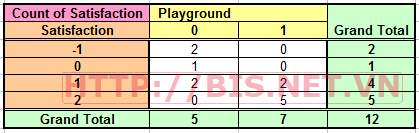
Giá trị trong bảng trên đây được lấy tổng hợp từ mẫu nên gọi là giá trị quan sát (Observe value)
Ví dụ, giá trị độc lập của ô tại dòng 3 cột 2, ta có Satisfaction = 1 và Playground = 1, ta có 2 trả lời (respondent). Ta có tổng dòng là 4 và tổng cột là 7. Tổng toàn bộ dữ liệu là 12 cho nên giá trị độc lập cho ô (cell) này là 4*7/12 = 2.333.
Thực hiện tương tự ta có giá trị độc lập cho tất cả các ô còn lại của bảng như sau:
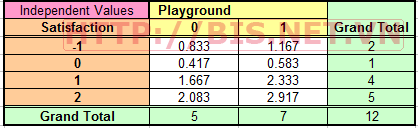
Giá trị kỳ vọng là giá trị tính được với giả thuyết H0 đúng. (ở đây giả thuyết H0 là : Giữa Playground và Satisfaction không có mối quan hệ)
Bảng này có nghĩa là nếu biến Playground hoàn toàn (100%) độc lập với Satisfaction thì giá trị quan sát trong Pivot Table phải bằng với với những giá trị kỳ vọng trong bảng này.
Kiểm định Chi-square (Chi-squre Test): Kiểm định Chi-square dùng để kiểm định sự độc lập của 2 biến phân loại ngẫu nhiên. Nếu xác suất nhỏ hơn 0.05 (5%, mức ý nghĩa) thì có thể kết luận 2 biến có mối quan hệ. Ngược lại, không có cơ sở để kết luận giữa 2 biến có mối quan hệ.
Xác suất đó có thể được tính trong Excel bằng hàm kiểm định Chi-square như sau
![]()
Trong đó :
![]() : Giá trị Chi-square (Chi-square value)
: Giá trị Chi-square (Chi-square value)
df: Bậc tự do (degree of freedom)
Để tính xác suất này, ta phải tính bình phương độ lệch giữa giá trị quan sát (observe value) từ Pivot Table và giá trị kỳ vọng (expected value) từ Independent table và chia cho giá trị kỳ vọng rồi tính tổng tất cả các độ lệch này trong bảng. Giá trị này gọi là giá trị Chi-square. Công thức tính như sau:
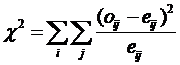
Bậc tự do (df – degree of freedom) được tính là tổng số hàng trừ 1 nhân với tổng số cột trừ 1
df = (total rows- 1)*(total columns -1)
Từ dữ liệu trong ví dụ trên ta tính tổng bình phương các độ lệch bằng 7.886 và bậc tự do df = (4-1)*(2-1)=3. Sử dụng hàm CHIDIST (7.886, 3) ta có xác suất p=0.048 (xem bảng dữ liệu sau)
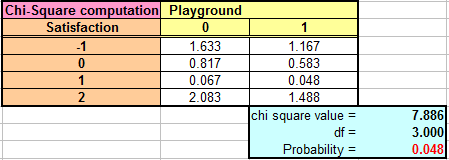
Vì xác suất p=0.048 nhỏ hơn 0.05 (mức ý nghĩa 5%) nên ta có thể kết luận rằng tồn tại mối quan hệ giữa playground và Satisfaction level (nói theo lý thuyết kiểm định giả thuyết là bác bỏ H0). Phân tích này cho phép trả lời câu hỏi nghiên cứu 4 ở trên. Có nghĩa là nếu công viên có sân chơi cho trẻ em thì sẽ làm tăng mức độ hài lòng của khách.
Từ Chi-square value và bậc tự do (degree of freedom ), sử dụng hàm CHIDIST(Chi-square value, degree of freedom) để tính xác suất p và so sánh p với mức ý nghĩa α (thường α=5%) ta có thể kết luận có tồn tại mối quan hệ giữa các biến hay không?. Ngược lại nếu biết xác suất p và bậc tự do ta có thể sử dụng hàm CHIINV(probability, degree of freedom) để tìm được Chi-square value.
Ta có thể sử dụng Chi-square value tính được bằng hàm CHIINV với xác suất p=0.05 so sánh với Chi-square value tính được từ bảng dữ liệu. Nếu giá trị Chi-square tính được từ hàm CHINV nhỏ hơn Chi-square value tính được từ bảng thì ta có thể kết luận giữa các biến có mối quan hệ. Chẳn hạn trong ví dụ trên, sử dụng hàm =CHIINV(0.05,3) ta sẽ có được Chi-square value là 7.815 nhỏ hơn Chi-square value tính được từ bảng là 7.886 nên ta kết luận giữa Playground và Satisfaction có mối quan hệ.
(Nếu bạn chưa quen với kiểm định Chi-square thì xem thêm về Chi-square test tại đây)
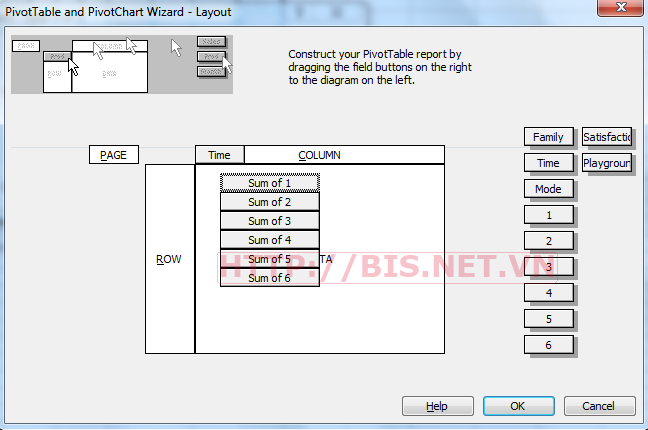
Để trả lời câu hỏi nghiên cứu 5 : Có mối quan hệ (tương quan) giữa hoạt động (activity) mà khách chọn và thời gian hoạt động (time) của khách không? Ta làm tương tự các bước như trên để tạo ra Pivot table của Activity và Time như sau:
Kéo thả biến Time button lên column và kéo thả tất cả các Activity (từ 1 đến 6) vào vùngData. Chọn hàm sum vì activity có kiểu dữ liệu binary (1 và 0) như sau:
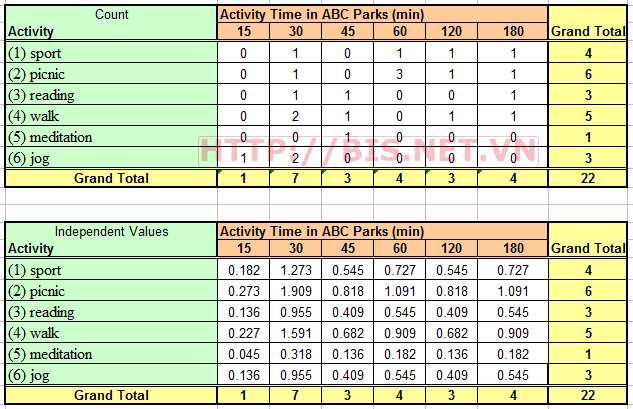
Thực hiện tính toán giống như phần trả lời câu hỏi 4 ta được kết quả phân tích như sau:
Chi-square test
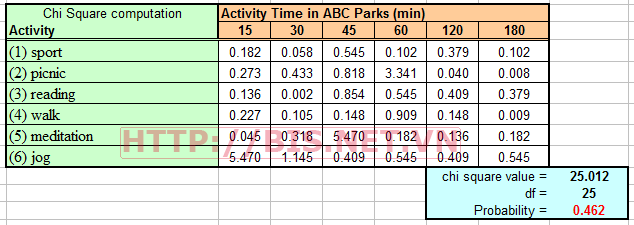
Vì xác xuất p=0.462 lớn hơn 0.05 nên ta kết luận không có mối quan hệ giữa hoạt động và thời gian hoạt động của khách.
Nếu ta sử dụng hàm CHIINV(0.05, 25) ta tính được Chi-square value =37.652 >25.012 nên kết luận tương tự là không có mối quan hệ giữa hoạt động và thời gian hoạt động của khách.
Đối với câu hỏi nghiên cứu cuối cùng, câu hỏi số 6: Có mối quan hệ (tương quan) giữa thời gian mà khách lưu lại công viên với phương tiện (mode) mà họ sử dụng để đến công viên không?
Ta xây dựng bảng Pivot table cho 2 biện Time và Mode như sau: Kéo thả Time vào Column và Mode và Row. Kéo thả Mode một lần nữa vào vùng Data và chọn hàm Countnhư sau:
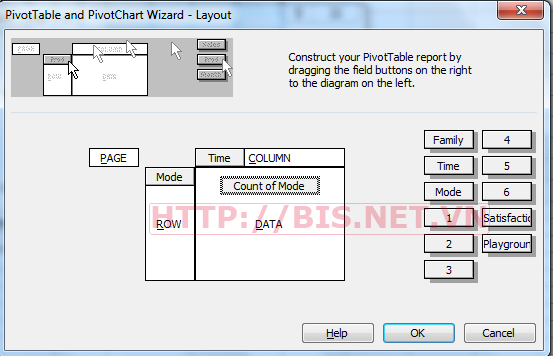
Kết quả phân tích tiến hành tương tự như trên ta có:
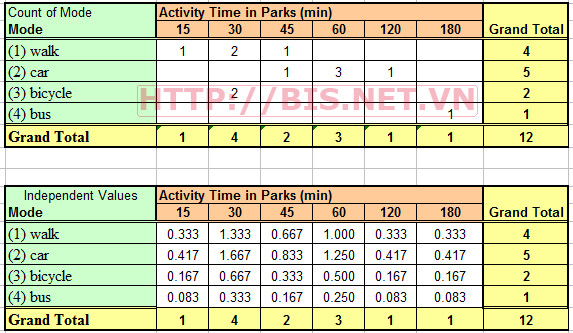
Chi- square Test
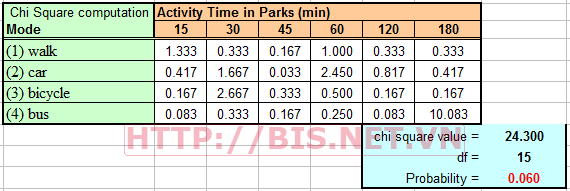
Vì p=0.06 >0.05 nên ta kết luận không có mối quan hệ giữa phương tiện mà khách sử dụng để đi đến công viên với thời gian hoạt động của khách tại công viên.
Excel's Statistical Functions - Các Hàm Thống kê trong MS Excel
Dương Đức Minh: Ngồi lọ mọ mãi với SPSS cuối cùng rồi cũng xong, xong rồi thì lại phân vân không biết mình làm đúng hay sai. Thôi thì Google cách kiểm tra lại qua Excel. Quá nhiều cái hay mà trước giờ mình không quan tâm nên không biết.
NHÓM HÀM VỀ THỐNG KÊ
AVEDEV (number1, number2, ...) : Tính trung bình độ lệch tuyệt đối các điểm dữ liệu theo trung bình của chúng. Thường dùng làm thước đo về sự biến đổi của tập số liệu
AVERAGE (number1, number2, ...) : Tính trung bình cộng
AVERAGEA (number1, number2, ...) : Tính trung bình cộng của các giá trị, bao gồm cả những giá trị logic
AVERAGEIF (range, criteria1) : Tính trung bình cộng của các giá trị trong một mảng theo một điều kiện
AVERAGEIFS (range, criteria1, criteria2, ...) : Tính trung bình cộng của các giá trị trong một mảng theo nhiều điều kiện
COUNT (value1, value2, ...) : Đếm số ô trong danh sách
COUNTA (value1, value2, ...) : Đếm số ô có chứa giá trị (không rỗng) trong danh sách
COUNTBLANK (range) : Đếm các ô rỗng trong một vùng
COUNTIF (range, criteria) : Đếm số ô thỏa một điều kiện cho trước bên trong một dãy
FREQUENCY (data_array, bins_array) : Tính xem có bao nhiêu giá trị thường xuyên xuất hiện bên trong một dãy giá trị, rồi trả về một mảng đứng các số. Luôn sử dụng hàm này ở dạng công thức mảng
MAX (number1, number2, ...) : Trả về giá trị lớn nhất của một tập giá trị
MAXA (number1, number2, ...) : Trả về giá trị lớn nhất của một tập giá trị, bao gồm cả các giá trị logic và text
MEDIAN (number1, number2, ...) : Tính trung bình vị của các số.
MIN (number1, number2, ...) : Trả về giá trị nhỏ nhất của một tập giá trị
MINA (number1, number2, ...) : Trả về giá trị nhỏ nhất của một tập giá trị, bao gồm cả các giá trị logic và text
MODE (number1, number2, ...) : Trả về giá trị xuất hiện nhiều nhất trong một mảng giá trị
PERCENTILE (array, k) : Tìm phân vị thứ k của các giá trị trong một mảng dữ liệu
PERCENTRANK (array, x, significance) : Trả về thứ hạng (vị trí tương đối) của một trị trong một mảng dữ liệu, là số phần trăm của mảng dữ liệu đó
QUARTILE (array, quart) : Tính điểm tứ phân vị của tập dữ liệu. Thường được dùng trong khảo sát dữ liệu để chia các tập hợp thành nhiều nhóm…
RANK (number, ref, order) : Tính thứ hạng của một số trong danh sách các số
SKEW (number1, number2, ...) : Trả về độ lệch của phân phối, mô tả độ không đối xứng của phân phối quanh trị trung bình của nó
NHÓM HÀM VỀ PHÂN PHỐI XÁC SUẤT
CHITEST (actual_range, expected_range) : Trả về giá trị của xác xuất từ phân phối chi-squared và số bậc tự do tương ứng.
CONFIDENCE (alpha, standard_dev, size) : Tính khoảng tin cậy cho một kỳ vọng lý thuyết
NORMDIST (x, mean, standard_dev, cumulative) : Trả về phân phối chuẩn (normal distribution). Thường được sử dụng trong việc thống kê, gồm cả việc kiểm tra giả thuyết
TTEST (array1, array2, tails, type) : Tính xác xuất kết hợp với phép thử Student.
ZTEST (array, x, sigma) : Trả về xác suất một phía của phép thử z.
PEARSON (array1, array2) : Tính hệ số tương quan momen tích pearson (r), một chỉ mục không thứ nguyên, trong khoảng từ -1 đến 1, phản ánh sự mở rộng quan hệ tuyến tính giữa hai tập số liệu
Excel thì không cần phải giới thiệu nữa rồi. Mình chỉ copy lại những cái gì mình đã dùng và đặc biệt hữu ích cho các nghiên cứu về khoa học xã hội, hành vi vốn dành cho những novice researcher như mình - người mà cứ nói đến toán là sợ, huống hồ sác xuất với lại thống kê :)
Mình chỉ copy lại nhũng gì quan trọng, còn cách sử dụng cụ thể và ví dụ minh họa thì đã có đầy đủ trong mục Help của Excel rồi.
AVEDEV (number1, number2, ...) : Tính trung bình độ lệch tuyệt đối các điểm dữ liệu theo trung bình của chúng. Thường dùng làm thước đo về sự biến đổi của tập số liệu
AVERAGE (number1, number2, ...) : Tính trung bình cộng
AVERAGEA (number1, number2, ...) : Tính trung bình cộng của các giá trị, bao gồm cả những giá trị logic
AVERAGEIF (range, criteria1) : Tính trung bình cộng của các giá trị trong một mảng theo một điều kiện
AVERAGEIFS (range, criteria1, criteria2, ...) : Tính trung bình cộng của các giá trị trong một mảng theo nhiều điều kiện
COUNT (value1, value2, ...) : Đếm số ô trong danh sách
COUNTA (value1, value2, ...) : Đếm số ô có chứa giá trị (không rỗng) trong danh sách
COUNTBLANK (range) : Đếm các ô rỗng trong một vùng
COUNTIF (range, criteria) : Đếm số ô thỏa một điều kiện cho trước bên trong một dãy
FREQUENCY (data_array, bins_array) : Tính xem có bao nhiêu giá trị thường xuyên xuất hiện bên trong một dãy giá trị, rồi trả về một mảng đứng các số. Luôn sử dụng hàm này ở dạng công thức mảng
MAX (number1, number2, ...) : Trả về giá trị lớn nhất của một tập giá trị
MAXA (number1, number2, ...) : Trả về giá trị lớn nhất của một tập giá trị, bao gồm cả các giá trị logic và text
MEDIAN (number1, number2, ...) : Tính trung bình vị của các số.
MIN (number1, number2, ...) : Trả về giá trị nhỏ nhất của một tập giá trị
MINA (number1, number2, ...) : Trả về giá trị nhỏ nhất của một tập giá trị, bao gồm cả các giá trị logic và text
MODE (number1, number2, ...) : Trả về giá trị xuất hiện nhiều nhất trong một mảng giá trị
PERCENTILE (array, k) : Tìm phân vị thứ k của các giá trị trong một mảng dữ liệu
PERCENTRANK (array, x, significance) : Trả về thứ hạng (vị trí tương đối) của một trị trong một mảng dữ liệu, là số phần trăm của mảng dữ liệu đó
QUARTILE (array, quart) : Tính điểm tứ phân vị của tập dữ liệu. Thường được dùng trong khảo sát dữ liệu để chia các tập hợp thành nhiều nhóm…
RANK (number, ref, order) : Tính thứ hạng của một số trong danh sách các số
SKEW (number1, number2, ...) : Trả về độ lệch của phân phối, mô tả độ không đối xứng của phân phối quanh trị trung bình của nó
NHÓM HÀM VỀ PHÂN PHỐI XÁC SUẤT
CHITEST (actual_range, expected_range) : Trả về giá trị của xác xuất từ phân phối chi-squared và số bậc tự do tương ứng.
CONFIDENCE (alpha, standard_dev, size) : Tính khoảng tin cậy cho một kỳ vọng lý thuyết
NORMDIST (x, mean, standard_dev, cumulative) : Trả về phân phối chuẩn (normal distribution). Thường được sử dụng trong việc thống kê, gồm cả việc kiểm tra giả thuyết
TTEST (array1, array2, tails, type) : Tính xác xuất kết hợp với phép thử Student.
ZTEST (array, x, sigma) : Trả về xác suất một phía của phép thử z.
PEARSON (array1, array2) : Tính hệ số tương quan momen tích pearson (r), một chỉ mục không thứ nguyên, trong khoảng từ -1 đến 1, phản ánh sự mở rộng quan hệ tuyến tính giữa hai tập số liệu
Nguồn: Giải pháp excel.com
Sunday, December 11, 2011









Saturday, December 10, 2011
Gương học tập, ý chí và nghị lực
Học hết cấp ba, anh đi xuất khẩu lao động, rồi về nước năm 1988. Một thời gian anh phải buôn xe đạp để mưu sinh. Nhưng không vì thế mà khát vọng tri thức trong anh lụi tàn, bằng cách nào đó, anh đã học xong hai bằng thạc sỹ kinh tế và cử nhân chính trị. Với nhiệt tình công tác, anh lần lượt trở thành phó Chủ tịch Trung ương hội Liên hiệp thanh niên Việt Nam, rồi phó Chủ nhiệm Ủy ban Dân tộc, phó bí thư, rồi bí thư tỉnh ủy Bắc Giang. Đại hội đảng lần thứ 11, người ta lại thấy tên anh trong danh sách trung ương ủy viên...
Đành rằng Nguyễn Thanh Nghị có thể thông minh hơn Nông Quốc Tuấn khi có bằng tiến sỹ ở Mỹ, nhưng về ý chí thì có khi đéo bằng!!!
Đành rằng Nguyễn Thanh Nghị có thể thông minh hơn Nông Quốc Tuấn khi có bằng tiến sỹ ở Mỹ, nhưng về ý chí thì có khi đéo bằng!!!
Nguồn; laothayboigia
Thursday, December 1, 2011
Exploring Statistical Methods in Social Sciences
Khám phá các phương pháp tính toán trong NCKH xã hội
Báo cáo tại Hội thảo KHXH Thời Hội nhập tổ chức ngày 15-12-2011 tại ĐHQG-HCM
Hai chữ khoa học trong khoa học xã hội có thể hiểu bằng nhiều nghĩa khác nhau, nhưng ở đây tôi muốn nói đến những khám phá tri thức mới có độ tin cậy và chính xác cao. Cách hiểu khoa học này thật ra xuất phát từ khoa học tự nhiên, nhưng cũng có thể áp dụng cho khoa học xã hội. Trong bài này, tôi sẽ bàn về việc ứng dụng khoa học thống kê (statistical science, chứ không phải đơn thuần thống kê học – statistics) như là một phương tiện để khám phá tri thức mới cho các nhà khoa học xã hội.
Các dữ liệu từ nghiên cứu khoa học xã hội thường rất phức tạp, vì mang tính đa biến và đa chiều. Khám phá những cơ cấu và mối liên hệ giữa các yếu tố trong một nghiên cứu là một thách thức lớn cho các nhà khoa học xã hội. Tuy nhiên, những phát triển trong khoa học thống kê đã giúp cho việc khám phá dễ dàng hơn. Ứng dụng của khoa học thống kê trong khoa học xã hội có thể chia thành hai nhóm: thiết kế nghiên cứu và suy luận khoa học.Bất cứ công trình nghiên cứu nào cũng khởi đầu từ khâu thiết kế, và khoa học thống kê đóng góp vào việc (a) chọn mô hình nghiên cứu thích hợp và tối ưu cho câu hỏi nghiên cứu; (b) ước lượng cỡ mẫu cần thiết cho mô hình nghiên cứu; cách lấy mẫu sao cho đảm bảo tính đại diện một quần thể.
Phân tích dữ liệu trong khoa học xã hội có thể chia thành hai nhóm chính: mô tả và suy luận. Mỗi nhóm phân tích đều có sự đóng góp của khoa học thống kê. Đối với phân tích mô tả, các phương pháp “cổ điển” như kiểm định Ki bình phương (Chi-squared test), kiểm định t, kiểm định z có thể ứng dụng để đáp ứng những câu hỏi nghiên cứu đơn giản. Rất nhiều phương pháp phân tích suy luận (inferential statistics) có thể ứng dụng cho các nghiên cứu khoa học xã hội. Các phương pháp định lượng mang tính suy luận bao gồm các mô hình phân tích hai biến (bivariate analysis) và đa biến (multivariate analysis) là những phương pháp quan trọng hỗ trợ cho nhà nghiên cứu trong việc thẩm định những mối tương quan phức tạp trong khoa học xã hội. Những phương pháp phân tích đa biến như phân tích yếu tố (factor analysis) và phân tích cụm (cluster analysis) còn giúp cho nhà nghiên cứu giảm độ phức tạp của cơ cấu dữ liệu, và dẫn đến những khám phá mà các phương pháp phân tích đơn giản không thể nào phát hiện được. Những mô hình như hồi qui tuyến tính, hồi qui logistic, hồi qui Poisson, hồi qui Cox cung cấp những phương tiện định lượng rất quan trọng trong việc khám phá các yếu tố có ảnh hưởng đến một sự cố hay hiện tượng xã hội.
.jpg)
Trong vài năm gần đây, khoa học thống kê đã có những phát triển ngoạn mục, và những phát triển này cung cấp cho khoa học xã hội những phương pháp định lượng để có những khám phá mới. Những phát triển mới trong mô hình tuyến tính cho phép nhà nghiên cứu phân tích những dữ liệu thu thập theo thời gian (longitudinal research). Với sự phát triển của máy tính, các nhà nghiên cứu khoa học xã hội đã có thể tiếp cận các phương pháp phân tích “hiện đại” như bootstrap và mô phỏng MCMC (Markov Chain Monte Carlo) mà trước đây chỉ dành cho các nhà khoa học thống kê chuyên nghiệp. Phương pháp MCMC cũng giúp cho các nhà khoa học xã hội có thể phân tích dữ liệu theo trường phái Bayes (Bayesian approach). Các phương pháp Bayes càng ngày càng trở nên hấp dẫn và quan trọng trong khoa học xã hội, vì các phương pháp này cho phép nhà nghiên cứu phát biểu về độ tin cậy của một giả thuyết khoa học dựa trên dữ liệu quan sát (thay vì phương pháp cổ điển chỉ cho phép nhà nghiên cứu phát biểu về dữ liệu quan sát trên cơ sở giả thuyết khoa học).
Ở nước ta, có một nghịch lí đáng chú ý: các nghiên cứu về khoa học xã hội hiện diện trên các tạp chí trong nước rất nhiều, nhưng lại xuất hiện rất ít trên các tạp chí khoa học quốc tế. Số liệu thống kê năm 2004 cho thấy trong số 8408 bài báo khoa học trong các tạp chí và kỉ yếu khoa học, có đến 4345 (hay 53%) là những bài báo liên quan đến khoa học xã hội. Tuy nhiên, trong năm 2004, con số bài báo khoa học xã hội trên các tạp chí khoa học quốc tế chưa quá con số 10 bài. Ngoài ra, phân tích của chúng tôi cho thấy trong thời gian 1996 – 2005, trong tổng số 3456 bài báo khoa học từ Việt Nam trên các tạp chí quốc tế, chỉ có 69 bài (tức khoảng 2%) liên quan đến ngành khoa học xã hội. Do đó, tuy số lượng nghiên cứu khoa học xã hội ở nước ta cao hơn so với các ngành khoa học tự nhiên, nhưng đại đa số những nghiên cứu đó chỉ xuất hiện trên các tạp chí trong nước, và rất ít xuất hiện trên các tạp chí quốc tế.
Một trong những “nguyên nhân” cho sự hiện diện khiêm tốn của khoa học xã hội Việt Nam trên trường quốc tế là vấn đề phương pháp định lượng. Có thể nói rằng phần lớn những nghiên cứu khoa học xã hội ở Việt Nam chưa tận dụng những phương pháp khoa học (scientific method) và phương pháp thống kê trong việc thiết kế nghiên cứu, phân tích dữ liệu, và diễn giải dữ liệu. Một số nghiên cứu có sử dụng phương pháp thống kê, nhưng chưa hẳn có hệ thống và chưa thích hợp. Nhiều sai sót hiển nhiên về cách lấy mẫu, phân tích và suy luận từ dữ liệu có thể tìm thấy trong rất nhiều bài báo trong ngành khoa học xã hội. Những thiếu sót về phương pháp dẫn đến chất lượng nghiên cứu chưa được cao, và hệ quả là nhiều công trình khó có cơ hội để được công bố trên các tạp chí khoa học xã hội quốc tế.
Ở các nước tiên tiến, khoa học thống kê (statistical science) đóng một vai trò rất quan trọng trong việc phát triển khoa học xã hội. Từ năm 1965, báo cáo Hội đồng Nghiên cứu Khoa học Xã hội ở Anh (Social Science Research Council) nhấn mạnh rằng nếu không có thống kê học và toán học, thì khoa học xã hội không thể nào phát triển được. Do đó, khoa học xã hội ở nước ta cần đến khoa học thống kê để phát triển. Khoa học thống kê có thể giúp cho các nhà khoa học xã hội phân tích mô tả và phân tích suy luận, và dẫn đến những khám phá có ý nghĩa thực tế và giúp cho việc hoạch định các chính sách công hữu hiệu hơn.

Subscribe to:
Posts (Atom)